訳:Auto Scaling in the Amazon Cloud
NetFlixのブログ。
http://techblog.netflix.com/2012/01/auto-scaling-in-amazon-cloud.html
====
2010年に本番環境をクラウドに移行し始めてから、動いているすべてのサーバプールを管理するためにオートスケーリングを使っている。オートスケーリングは、我々のサービスの可用性を素晴らしく解決し、クラウドコストの最適化をもたらしている。オートスケーリングを2年以上使った経験から、なぜ?どのように使っているのかという我々が得た教訓を共有する頃と考えた。オートスケーリングに馴染みのない人のために、、Amazonが提供しているクラウド機構の一つで自動化のサービスである。オートスケーリングは、実行中のサーバプールを管理する機能を提供する。故障したインスタンスを置き換える機能や、自動でプールサイズを伸縮する機能も備える。より詳しい説明は、Amazon Documentを参照してほしい。
利点( Benefits)
可用性(Availability)
本番環境の全サーバはオートスケーリンググループの一部である。サル軍(simian army)のメンバーか確認し、環境から外れたインスタンスは終了する。この目的は、素早く不健全なインスタンスを検出し終了させることである。Amazonによりその検出と置換が自動化されている。Amazonにより終了させられた場合やハード故障の場合のホストにも適用される。ステートフルとステートレスのどちらのサービスでも機能する。というのも、ステートフルサービスでも、AMIが起動した時にどうセットアップすればよいかを知っているからである。サービスのほとんどがステートレスであるが、最適化のためにオートスケーリングを使う機会を与えている。
最適化( Optimization )
オートスケーリングの最重要な用途は可用性といっているが、コストとリソース最適化も大事な側面である。必要に応じてリソースを配備可能であることと、従量課金であることは、クラウドの大きな契約の一つである。ごく一部のアプリケーションは一定の負荷だが、Netflixは例外ではない。実際、ピークへの利用パターンは様々である。オートスケーリングは、使用率に応じて節約できるとても大きなプールサイズも可能にし、不足のスパイクにも適応し、サービス停止やマニュアルでのキャパシティ調整が不要である。
動作させる (Maging it Work )
オートスケーリングを設定するのは複雑なタスクだ。大雑把に、設定は3段階である。まず、メモリやCPU等のリソースの条件を決める。次に、Amazonクラウドのリソース監視サービスであるCloudWatchで決めた条件の追跡方法を選ぶ。最後に、リソースの条件が変化した場合にアラームや正しいアクションを行うポリシーと関連付けるプロファイルを設定する。すべてのアプリにとって、AWSが提供する唯一利用できるメトリクスであるCPU使用率は大きなインジケーターにはならない。我々は2段階のtoolingと、簡単に行えるようにいくつかのスクリプトを作成した。
最初の段階のツールは、アプリケーションのメトリクスをエクスポートしてCloudWatchに提供するモニタリングライブラリだ。開発者は簡単にエクスポートすることができる。あるフィールドが " @Monitor"タグでアノテートされていれば、自動的にJMXに登録され、configurable filsterに基づいてCloudWatchにパブリッシュされる。さらなる重要な機能は、オートスケーリングの設定で使われるフィールドをエクスポートするために抽出する事。このライブラリのオープンソース化の話題を見て欲しい。(訳注:Announcing Servo )
2段階目のツールは、Netflix Application Console(slide)への組み込みである。我々のクラウド基盤全体のドライバーになるが、オートスケーリングを簡単に作るために追加した。プッシュプロセスの一部として、新しいバージョンのコード用に新しいオートスケーリンググループを作る。古いグループの全設定を新しいグループに確実にコピーする必要があることを意味する。ルール設定をシンプルなHTMLで表示し、ユーザに編集できるようにしている。加えて、オートスケーリングのルールのセットアップ、SNS通知設定、ロールバックオプション作成を助けるシンプルなスクリプトもある。スクリプトは github siteで確認できる。
動的なオートスケーリングをきちんと動作させるため、最後で最も重要なことは、負荷状況におけるアプリケーションの振る舞いを理解しテストすること。本番環境の少ないサーバセットに対して、トラフィックを絞って両方行なっている。負荷時にアプリケーションがどう振る舞うか、もしくはアプリケーションの本当の上限が何か、を知らないことは、オートスケーリングが効果的にならないか破壊的な結果になるだろう。
最終結果
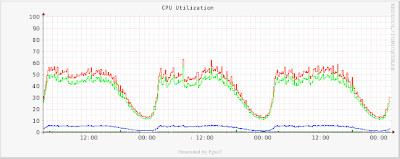
以下のグラフは、2日間のリクエストトラフィックである。サーバ数と、プールのCPU利用率集計である。サーバ数が、リクエストレートに反映されていることと、CPU集計の負荷が特にフラットであることに注意して欲しい。


学んだこと
早くスケールアップ、遅くスケールダウン(Scale up early, Scale down slowly)
Netflixでは、早くスケールアップさせ、ゆっくりスケールダウンさせるようにしている。対称的なパーセンテージと、定期的なオートスケーリングポリシーとCloudWatchのアラームを使うようにチームに支持している。くわしくはこちら
早くスケールアップするために、CloudWatchアラームを短期間(5-10分)に75%に達する設定を推奨している。インスタンス開始に要する時間(EC2、アプリケーションの両方)を考慮している。25%の余裕で、イレギュラーなスパイクでキャパシティが不足しないようにしている。また、インスタンス開始失敗によるキャパシティ不足を防ぐ。例:CPU使用率が80%なら、アラームトリガーを5分後60%で設定する。
Scaling down slowly is important to mitigate the risk of removing capacity too quickly, or incorrectly reducing capacity. To prevent these scenarios we use time as a proxy to scaling slowly. For example, scale up by 10% if CPU utilization is greater than 60% for 5 minutes, scale down by 10% if CPU utilization is less than 30% for 20 minutes. The advantage to using time, as opposed to asymmetric scaling policies, is to prevent capacity 'thrashing', or removing too much capacity followed by quickly re-adding the capacity. This can happen if the scale down policy is too aggressive. Time-based scaling can also prevent incorrectly scaling down during an unplanned service outage. For example, suppose an edge service temporarily goes down. As a result of reduced requests associated with the outage, the middle tier may incorrectly scale down. If the edge service is down for less than the configured alarm time, no scale down event will occur.
Provision for availability zone capacity
Auto scaling policies should be defined based on the capacity needs per availability zone. This is especially critical for auto scaling groups configured to leverage multiple availability zones with a percent-based scaling policy. For example, suppose an edge service is provisioned in three zones with the min and max set to 10 and 30 respectively. The same service was load tested with a max 110 requests per second (RPS), per instance. With a single elastic load balancer (ELB), fronting the service, each request is uniformly routed, round robin, per zone. Effectively, each zone must be provisioned with enough capacity to handle one third of the total traffic. With a percent based policy one or more zones may become under provisioned. Assume 1850 total RPS, 617 RPS per zone. Two zones with 6 instances, the other having 5 instances, 17 total. The zones with 6 instances, on average, are processing 103 RPS per server. The zone with 5 instances, on average, are processing 124 RPS per instance, about 13% beyond desired (load tested) RPS. The root of the problem is the unbalanced availability zone. A zone can become unbalanced by scaling up/down by a factor less than the number of zones. This tends to occur when using a percent based policy. Also note, the aggregate, computed by CloudWatch, is a simple, equally weighted, average, masking the under-provisioned zone.
結論
オートスケーリングはとても強力なツールであるが、諸刃の剣になりうる。正しい設定とテストなしでは、良い面より悪い面が出る。最適化やより複雑な設定をすると顕著なケース( a number of edge)も出てくるだろう。このように、慎重に正しく設定すると、オートスケーリングはコストを減らしながら可用性を上げることができる。より詳細に我々のツールや学んだことを知りたければ、ソースとwikiのドキュメントがある auto scaling github projectを見てほしい。